Hanxiang Qin (秦瀚翔)

I am a Master’s student in Computer Science at Johns Hopkins University, advised by Alexander Martin and Prof. Benjamin Van Durme. My research focuses on efficient multimodal understanding and retrieval, with a particular emphasis on representation learning and context management.
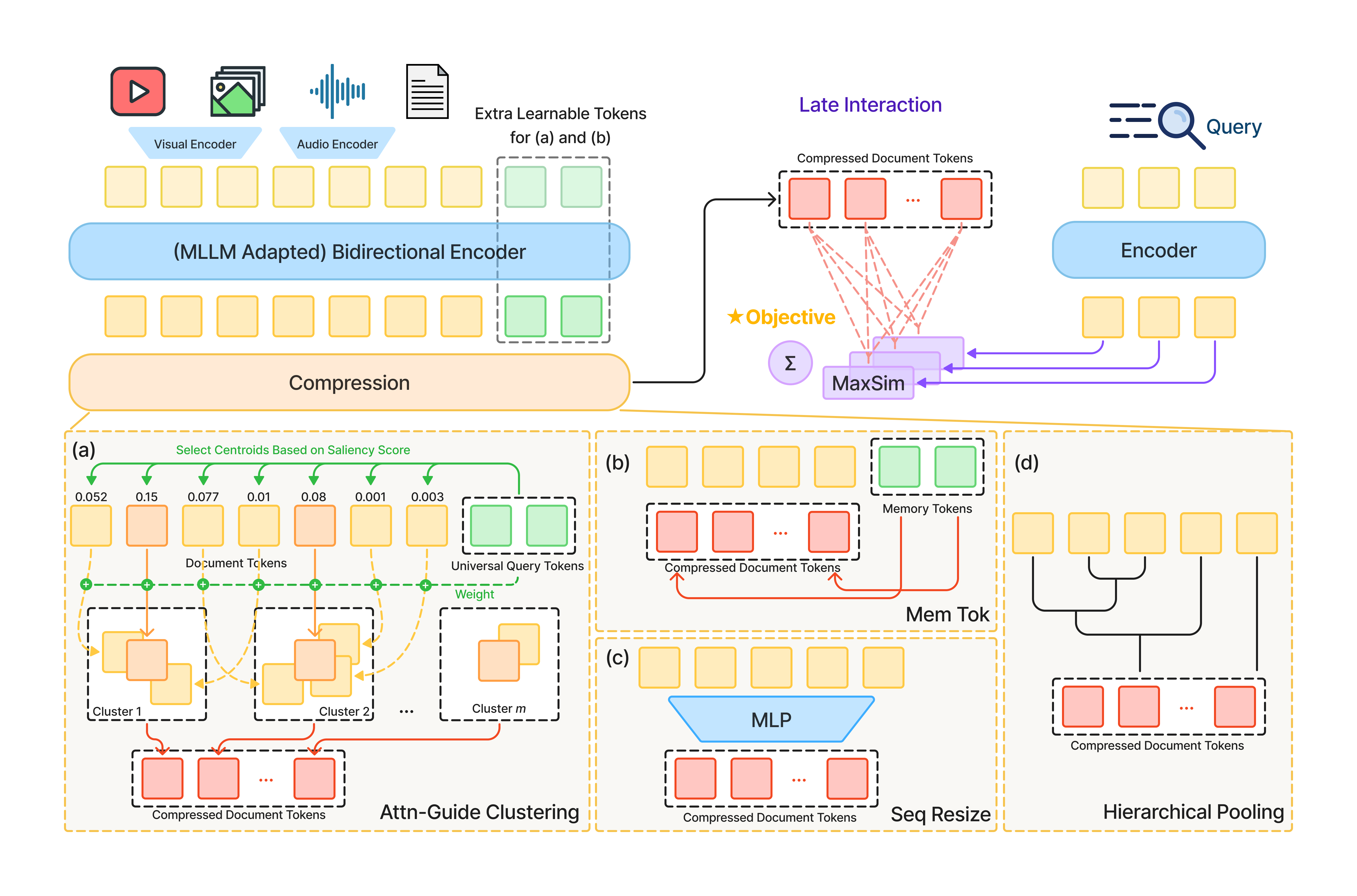
My recent work scales powerful but costly late-interaction models to be efficient in terms of compute and storage, unlocking their potential for the retrieval of notoriously token-heavy multimodal content spanning text, visual, and audio. We use just a 2.4%-4.9% footprint to preserve or even beat uncompressed state-of-the-art performance. Currently, I’m excited to start my new project on an agentic framework for high-fidelity video understanding.
Before coming to JHU, I was a Software Engineer at Pinduoduo (Temu) for three years, specializing in iOS and cross-platform development. Driven by a core focus on user experience and user growth, I led extensive performance optimizations and framework refactoring. My work empowered rapid product iteration at a massive scale, reliably serving hundreds of millions of daily active users (DAUs).
Previously, I earned a dual degree in Computer Science & Technology and Horticulture from Zhejiang University, where I was advised by Prof. Ming Cai.
News
| Feb 2026 | Excited to share our new paper “Multi-Vector Index Compression in Any Modality”! You can find the code on GitHub, and the released models on HuggingFace. |
|---|---|
| Jan 2026 | I’m a Course Assistant for 601.472/672: NLP for Computational Social Science this Spring! |
| Aug 2025 | I’m a Course Assistant for 601.465/665: Natural Language Processing! |
| Aug 2024 | Starting my Master’s study at JHU! |
| Jul 2020 | Working as a Software Engineer at Pinduoduo! |